-
 RUSSELL JAMES 30 Apr
RUSSELL JAMES 30 Apr

This is the first in a series of blogs on NPUs. This first blog deals with understanding exactly what an NPU is and isn’t. If this is known to the reader, please skip onto later blogs in the series.
There is a wealth of often confusing and overloaded terms when it comes to AI.
Machine Learning (ML), Neural Networks (NN), Deep Learning (DL), Training (the process by which the neural network is tuned to respond), Inference (running the trained neural network with a set of inputs and generating a result), AGI (Artificial General Intelligence) and many others.
All of these terms come under the umbrella of AI, but they all cover different aspects. Neural Processing Units (NPUs) are primarily responsible for AI or Neural Network inferencing in embedded/consumer devices like smartphones, laptops, tablets, home assistants (Alexa, HomeHub), smart home, smart cameras, wearables and many other devices.
Neural network inferencing can be run on any CPU or GPU, but the gotcha here is that the compute requirements are high and corresponding performance and power consumption are relatively poor as a result.
NPU stands for Neural Processing Unit. Like a GPU (graphical processing unit), the NPU was created for a specialised computation use case - Neural Network processing. The rise of AI applications across almost every market and technology has driven the need for NPUs, to enable higher inference runtime performance and significantly lower power consumption.
Going from CPU to GPU to NPU can result in up to an order of magnitude difference at each stage, in terms of NN inference runtime Performance per Watt. However, it is worth mentioning that this performance power improvement is not universal across all neural network operations and architectures, meaning that per use case testing and evaluation is always worthwhile to ensure the right compute core is being targeted for any given application.
This blog will focus on NPUs in embedded devices, which are predominantly modern smartphones.
NPUs are used for the on-device execution of neural networks, and the most common applications in use today are -
New and upcoming applications -
As of right now Embedded NPUs are not really used for LLM type inferencing. Applications using LLMs i.e. ChatGPT are almost exclusively run in the datacenter. Even Apple Intelligence, which was touted by Apple as being on device, runs simpler queries on device and defers to the datacenter to run more complex queries.
Whichever architecture is used for an NPU, they are ultimately limited by the hardware operations implemented in the core. NPUs are designed to massively accelerate neural network operations, but they do so at the expense of flexibility of compute. As neural networks develop and add new layers and operations, the overall capability of the NPU effectively decreases. To ensure that all neural networks can run on an embedded device, they are paired with GPU and CPU cores to pick up any slack. Moving data between GPU, CPU and NPU obviously comes at a cost in terms of inference runtime performance and power consumption.
To give an example of the difference in performance between CPU, GPU and NPU, the following results are based on the median inference time for MobileNetV2In8LUT Neural Network model (available on the official CoreML tools webpage here), running on Apple MacBook Pro M2 in XCode.
In the table below median inference time is displayed as “inferences per second”.
The power figures shown are that reported using an internal sensor data tool for each compute core - CPU, GPU and ANE.
Note - Internal power consumption data is not guaranteed to be 100% accurate, but it is accurate enough to show the scale of difference between the different compute cores.
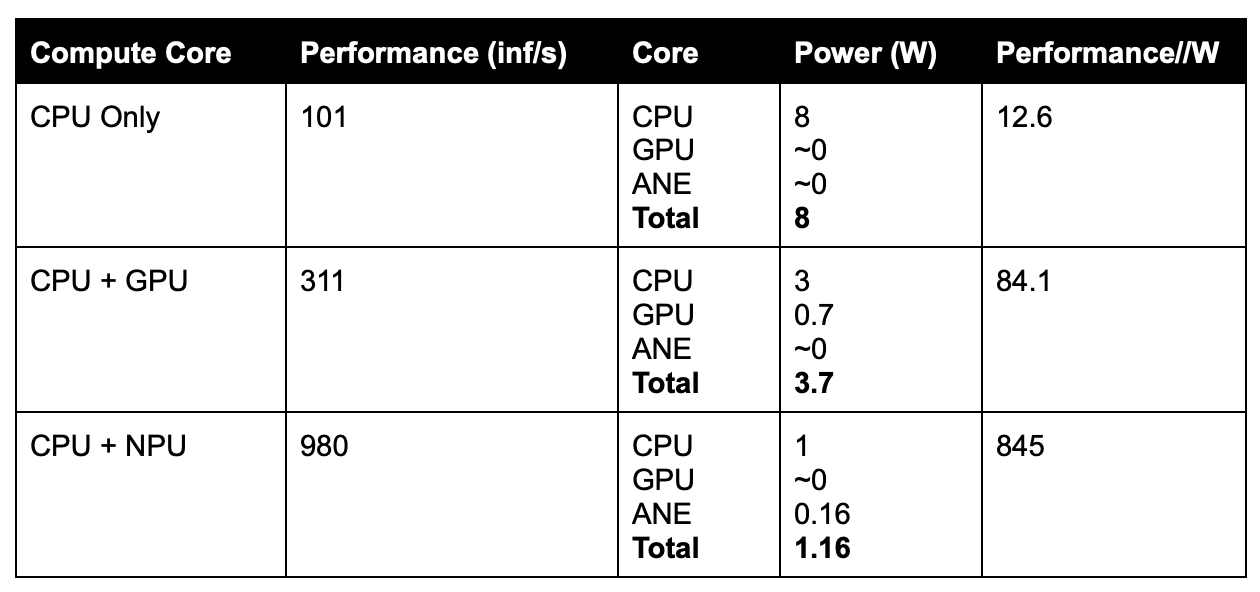
MobileNet is a deep convolution based network, designed for image classification and object detection. As an illustrative example, rather than a rigorous experiment, these results show that the efficiency of this specific neural network, scales NN inference/Watt computation by 7x between CPU and GPU and an order of magnitude between GPU and ANE.
Picking a different neural network will obviously generate results that are dependent on how well the network architecture matches the computation offered by the NPU hardware.
There are multiple NPU architecture types at present, but the dominant one is the Von Neumann type. Note that the Google TPU differs from this by following a systolic array type architecture.
There are also several architectures in development that utilise systolic arrays, in-memory compute or full analogue neuron based compute components. These architectures all promise to significantly reduce the power consumption and increase the performance of tiny to very large scale neural network inferencing.
Whilst a Von Neumann architecture is that of a CPU, the same principles are used for NPUs - there is a compute core, a memory bus attached to external and internal memory (DDR and embedded SRAM) and a program control unit/scheduler.
The compute core element of the NPU is the MAC Array (Multiply Accumulate Core) or MM (Matrix Multiplier) Array. The MAC/MM array is excellent at performing large scale convolutions and matrix multiply operations, which are a core function of many neural networks. In addition embedded NPUs will contain support for common NN operations such as pooling, normalisation and activations.
The memory bus connects the compute units to both internal on-chip SRAM and optionally external DDR. SRAM facilitates high speed data movement for both weights and intermediate data used for NN operations. However, it is the local storage limitations that either restrict the types of networks that can be accelerated on NPUs, or necessitate the use of much slower and higher power external DDR.
Large networks like LLMs require massive amounts of data storage for inferencing (for both the network weights and intermediate data) and on-device NPUs simply do not have the capacity for this.
A typical Von Neumann NPU architecture -
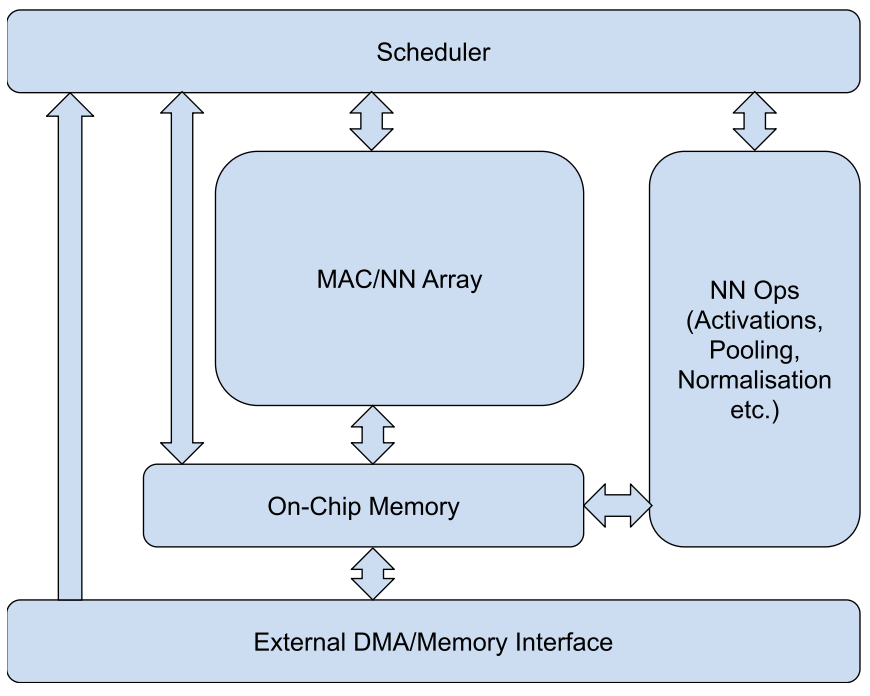
At a high level, this architecture will follow a set of compile time determined instructions - a program. The program contains fundamental commands i.e. fetch data from location A, run a set of algorithmic operations on the data, write data to location B. The NPU includes support for many different NN operations, from multiple variations of convolutions, matrix multiplication, normalisation, pooling, memory ops, activations etc.
The more operations implemented in the hardware, the greater the breadth of neural network architectures can be supported.
NPUs of this type often support fixed point operations, in favour of floating point, although FP16 is available for some NPUs. Fixed point maths uses less silicon area and consumes less power, than floating point maths. To give an idea of scale, the difference in silicon area between floating point multiplication and fixed point multiplication can be anything from 2-6 times larger for floating point (depending on the size and architecture of the multiplier).
From an architectural standpoint, there are multiple ways to solve the problems of neural network computation, with the most popular ones being the ones that utilise existing mainstream silicon technology and are fully digital by design.
However, there are other solutions that incorporate both digital and analogue designs (mixed signal), such as in-memory NN compute.
Even with modern NPUs, power consumption and runtime performance can still be lacking due to the massive scale of compute required and analogue in-memory computation offer a means to reduce power and increase speed over current NPUs, by an order of magnitude or more. Data movement is one of the biggest costs in power and performance which in-memory compute can significantly reduce. Within the realm of analogue and in-memory computation of neural networks, there are multiple implementations, for example “spiking neural networks” allow for a closer match to how the human brain works.
Currently there are not many NPUs of these types in production, but the demand for AI continues to grow and that growth will fuel innovation and variety in the future.
Unfortunately, unlike graphics on embedded GPUs (OpenGL and Vulkan for GPU), there are no truly standardised APIs for embedded NPUs.
Attempts have been made to standardise the mapping of AI frameworks through to NPU APIs and drivers in the past, but with little sustained success.
Whilst at the AI framework level, Pytorch has been hugely successful in becoming a de facto framework of choice, the efforts around executing NN inference on NPUs has not managed to coalesce into a common methodology or standard.
There are some standards such as Google Android Neural Networks API (NNAPI), TVM, ONNX Runtime and TensorFlow Lite/LiteRT, but either support or performance is often lacking.
The end result is that each NPU vendor has their own set of proprietary APIs and tools e.g. CoreML for Apple Neural Engine (ANE) and Hexagon QNN for Qualcomm Snapdragon Hexagon NPUs.
A typical NPU software framework is as follows -
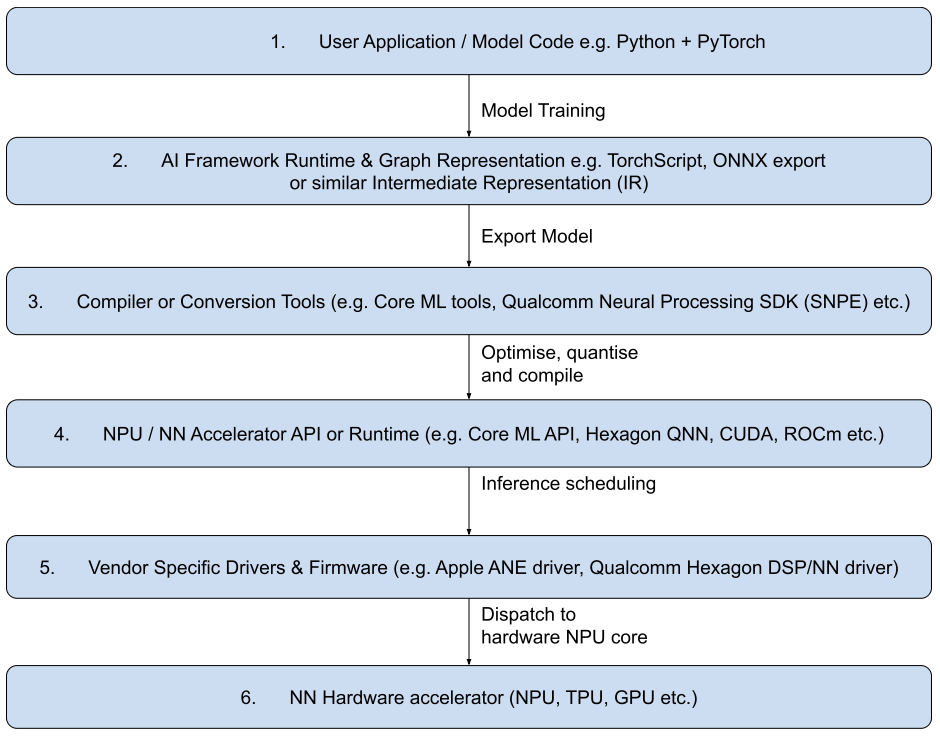
It is important to note that with NPU cores in embedded systems today, most run with different data types and bit depths (fixed point 8 bit) to the Neural Networks trained on GPUs (floating point 32 bit) in the datacenter.
Referencing the diagram above, this does result in a different network inference behaviour running at stage 6, compared to the original network at stage 1.
These differences can be trained or optimised away using modern neural network quantisation and retraining techniques.
Stay tuned for the next instalment, “The NPU Landscape in 2025”, in this series later this year.

 MYLES DOYLE
MYLES DOYLE
 BILAL ABBASI
BILAL ABBASI
 LEWIS BRESLIN
LEWIS BRESLIN